
SQL ابزار کلیدی برای مدیریت و پردازش دادهها در دیتابیسهای رابطهای است. با رشد روزافزون حجم دادهها، نوشتن کوئریهای پیچیده برای بازیابی اطلاعات چالشبرانگیز شده است.
کوئریهای کند میتوانند عملکرد برنامهها و تجربه کاربری را مختل کنند. بهینهسازی کوئری SQL نهتنها عملکرد سیستم را بهبود میبخشد، بلکه مصرف منابع را کاهش داده و مقیاسپذیری دیتابیس را تضمین میکند.
در این مقاله، مؤثرترین تکنیکهای بهینهسازی SQL را بررسی میکنیم و با تحلیل مزایا و معایب هر روش، تأثیر آنها بر بهینهسازی دیتابیس و کاهش زمان پاسخگویی کوئری را توضیح میدهیم.
| پیشنهاد مطالعه: آموزش اتصال به SQL Server: راهنمای گامبهگام و تصویری |
تکنیکهای بهینهسازی کوئری SQL
کوئریهای ناکارآمد یا دارای خطا میتوانند منابع زیادی در دیتابیس تولیدی مصرف کنند و منجر به عملکرد کندتر یا حتی قطع ارتباط سایر کاربران شوند. بهینهسازی کوئری SQL برای کاهش فشار روی دیتابیس و تضمین اجرای سریعتر دستورات ضروری است.
در این بخش، چندین تکنیک عملی برای بهینهسازی کوئری SQL همراه با مثالهای کاربردی ارائه میشود. این روشها بر بهبود کارایی دیتابیس و کاهش زمان پاسخگویی کوئریها تمرکز دارند و تجربه کاربری روانتری ایجاد میکنند.
1. ایندکسگذاری مناسب: کلید بهینهسازی کوئری SQL
تصور کنید در یک کتابخانه بدون فهرست به دنبال کتابی هستیم. باید هر قفسه و هر ردیف را بررسی کنیم تا بالاخره آن را پیدا کنیم. ایندکسها در دیتابیس مشابه فهرستهای کتابخانه هستند. آنها به ما کمک میکنند تا دادههای موردنیاز را بدون اسکن کل جدول بهسرعت پیدا کنیم.
نحوه عملکرد ایندکسها
ایندکسها ساختارهای دادهای هستند که سرعت بازیابی دادهها را بهبود میدهند. آنها با ایجاد یک کپی مرتبشده از ستونهای ایندکسشده عمل میکنند که به دیتابیس امکان میدهد ردیفهای مطابق با کوئری را بهسرعت پیدا کند و زمان زیادی صرفهجویی شود.
سه نوع اصلی ایندکس در دیتابیسها وجود دارد:
- Clustered Indexها: دادهها را بر اساس مقادیر ستون بهصورت فیزیکی مرتب میکنند و برای دادههای متوالی یا مرتبشده بدون تکرار، مانند Primary Keyها، بهترین انتخاب هستند.
- Non-Clustered Indexها: دو ستون جداگانه ایجاد میکنند و برای جدولهای نگاشت یا واژهنامهها مناسباند.
- Full-Text Indexها: برای جستجو در فیلدهای متنی بزرگ، مانند مقالات یا ایمیلها، استفاده میشوند و موقعیت اصطلاحات در متن را ذخیره میکنند.
چگونه میتوانیم از ایندکسها برای بهبود عملکرد کوئریهای SQL استفاده کنیم؟ چند بهترین روش:
- ایندکسگذاری ستونهای پراستفاده در کوئریها: اگر معمولاً یک جدول را با استفاده از customer_id یا item_id جستجو میکنیم، ایندکسگذاری این ستونها تأثیر زیادی بر سرعت خواهد داشت. مثال:
CREATE INDEX index_customer_id ON customers (customer_id); - اجتناب از ایندکسهای غیرضروری: اگرچه ایندکسها برای سرعت بخشیدن به کوئریهای SELECT بسیار مفیدند، اما میتوانند عملیات INSERT، UPDATE و DELETE را کمی کند کنند، زیرا ایندکس باید در هر تغییر داده بهروزرسانی شود. بنابراین، ایندکسهای بیش از حد میتوانند با افزایش سربار برای تغییرات داده، عملکرد را کاهش دهند.
- انتخاب نوع ایندکس مناسب: دیتابیسهای مختلف انواع ایندکسهای متفاوتی ارائه میدهند. باید نوعی را انتخاب کنیم که با دادهها و الگوهای کوئری ما سازگار باشد. برای مثال، ایندکس B-tree برای جستجوی محدودههای مقادیر گزینه خوبی است.
2. اجتناب از SELECT * برای افزایش سرعت کوئریها
استفاده از SELECT * باعث بازیابی دادههای غیرضروری شده و عملکرد کوئری را کاهش میدهد. برای بهینهسازی کوئری SQL، فقط ستونهای مورد نیاز را انتخاب کنید.
گاهی اوقات وسوسه میشویم از SELECT * برای گرفتن تمام ستونها استفاده کنیم، حتی ستونهایی که برای تحلیل ما مرتبط نیستند. اگرچه این کار ممکن است راحت به نظر برسد، اما منجر به کوئریهای بسیار ناکارآمدی میشود که عملکرد را کند میکنند.
دیتابیس باید دادههای بیشتری از آنچه لازم است بخواند و منتقل کند، که نیاز به حافظه بیشتری دارد، زیرا سرور باید اطلاعات بیشتری را پردازش و ذخیره کند.
بهعنوان یک روش کلی، باید فقط ستونهای موردنیاز را انتخاب کنیم. کاهش دادههای غیرضروری نهتنها کد را تمیز و خوانا نگه میدارد، بلکه عملکرد را نیز بهینه میکند.
بهجای نوشتن:
SELECT *
FROM products;باید بنویسیم:
SELECT product_id, product_name, product_price
FROM products;3. اجتناب از بازیابی دادههای غیرضروری یا تکراری
در بخش قبل گفتیم،انتخاب فقط ستونهای مرتبط یک روش بهینه برای کوئریهای SQL است. با این حال، محدود کردن تعداد ردیفهای بازیابیشده نیز مهم است، نه فقط ستونها. کوئریها معمولاً با افزایش تعداد ردیفها کند میشوند.
میتوانیم از LIMIT برای کاهش تعداد ردیفهای بازگرداندهشده استفاده کنیم. این قابلیت از بازیابی غیرعمدی هزاران ردیف داده جلوگیری میکند، زمانی که فقط نیاز به کار با تعداد کمی داریم.
استفاده از LIMIT یا شرایط WHERE دقیق باعث کاهش تعداد ردیفهای بازگرداندهشده و افزایش سرعت کوئری میشود.
مثال استفاده از LIMIT:
SELECT name
FROM customers
ORDER BY customer_group DESC
LIMIT 100;4. استفاده کارآمد از Joinها
هنگام کار با دیتابیسهای رابطهای، دادهها اغلب در جدولهای جداگانه سازماندهی میشوند تا از تکرار جلوگیری شده و کارایی بهبود یابد. با این حال، این بدان معناست که باید دادهها را از مکانهای مختلف بازیابی کرده و به هم متصل کنیم تا تمام اطلاعات موردنیاز را به دست آوریم.
Joinها به ما امکان میدهند ردیفهایی از دو یا چند جدول را بر اساس یک ستون مرتبط در یک کوئری واحد ترکیب کنیم و تحلیلهای پیچیدهتری را ممکن میسازند.
انواع مختلفی از Join وجود دارد و باید نحوه استفاده از آنها را درک کنیم. استفاده از Join اشتباه میتواند باعث ایجاد دادههای تکراری در مجموعه داده ما شده و آن را کند کند.
- Inner Join: فقط ردیفهایی را که در هر دو جدول مطابقت دارند بازمیگرداند. اگر رکوردی در یک جدول وجود داشته باشد اما در جدول دیگر نه، آن رکورد از نتیجه حذف میشود.
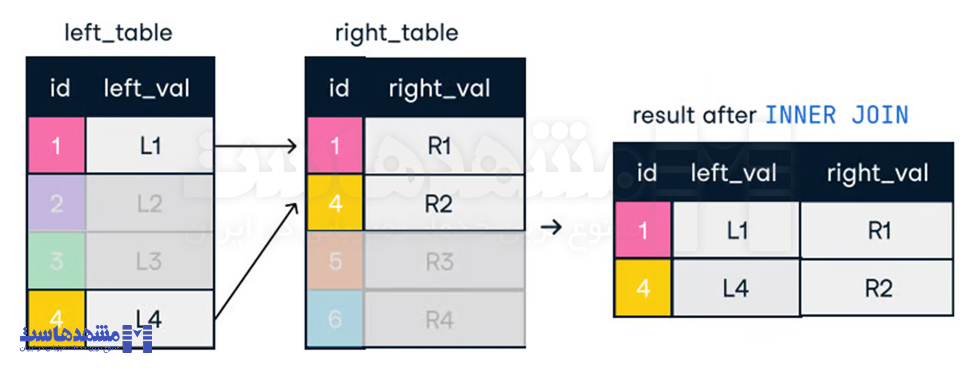
SELECT o.order_id, c.name
FROM orders o
INNER JOIN customers c ON o.customer_id = c.customer_id;- Outer Join (Full Outer Join): تمام ردیفها از یک جدول و ردیفهای مطابقتیافته از جدول دیگر را بازمیگرداند. اگر مطابقت وجود نداشته باشد، مقادیر NULL برای ستونهای جدول بدون ردیف مطابق بازگردانده میشود.
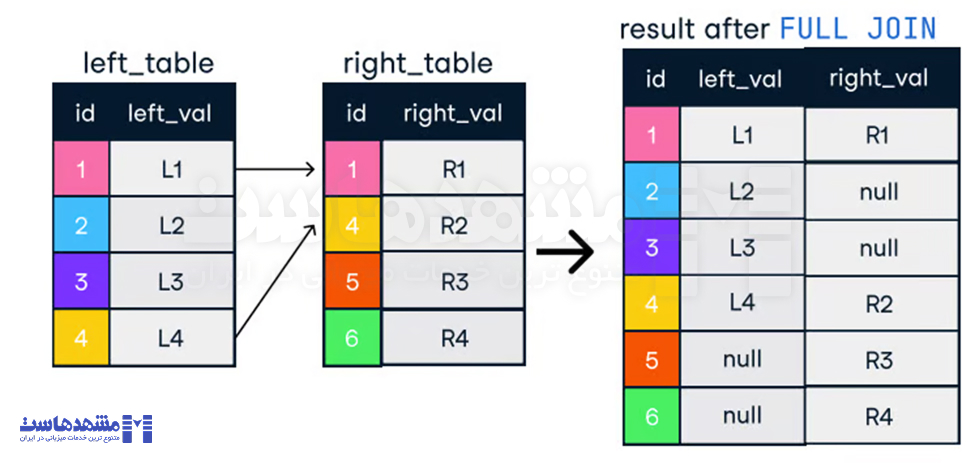
SELECT o.order_id, c.name
FROM orders o
FULL OUTER JOIN customers c ON o.customer_id = c.customer_id;- Left Join و Right Join: Left Join تمام ردیفها از جدول چپ و ردیفهای مطابقتیافته از جدول راست را شامل میشود. اگر مطابقت یافت نشود، مقادیر NULL برای ستونهای جدول راست بازگردانده میشود. Right Join برعکس عمل میکند.
SELECT c.name, o.order_id
LEFT JOIN orders o ON c.customer_id = o.customer_id;
FROM customers cنکات برای Joinهای کارآمد برای بهینهسازی کوئری SQL:
- ترتیب منطقی Joinها: با جدولهایی شروع کنید که کمترین تعداد ردیف را بازمیگردانند. این کار حجم دادههایی که باید در Joinهای بعدی پردازش شوند را کاهش میدهد.
- استفاده از ایندکسها در ستونهای Join: ایندکسها به دیتابیس کمک میکنند تا ردیفهای مطابقتیافته را سریعتر پیدا کند.
- استفاده از Subqueryها یا CTEها: برای سادهسازی Joinهای پیچیده، میتوان از Common Table Expressionها (CTEها) استفاده کرد:
WITH RecentOrders AS (
SELECT customer_id, order_id
FROM orders
WHERE order_date >= DATE('now', '-30 days')
)
SELECT c.customer_name, ro.order_id
FROM customers c
INNER JOIN RecentOrders ro ON c.customer_id = ro.customer_id5. تحلیل Execution Planهای کوئری
اغلب اوقات، کوئریهای SQL را اجرا میکنیم و فقط بررسی میکنیم که آیا خروجی یا نتیجه بهدستآمده همان چیزی است که انتظار داشتیم. اما بهندرت به این فکر میکنیم که پشت صحنه هنگام اجرای یک کوئری SQL چه اتفاقی میافتد.
استفاده از EXPLAIN یا EXPLAIN PLAN به شما کمک میکند گلوگاههای عملکردی را شناسایی و تصمیمات آگاهانه برای بهینهسازی کوئری SQL بگیرید.
مثال استفاده از EXPLAIN برای شناسایی گلوگاهها:
EXPLAIN SELECT f.title, a.actor_name
FROM film f, film_actor fa, actor a
WHERE f.film_id = fa.film_id AND fa.actor_id = a.id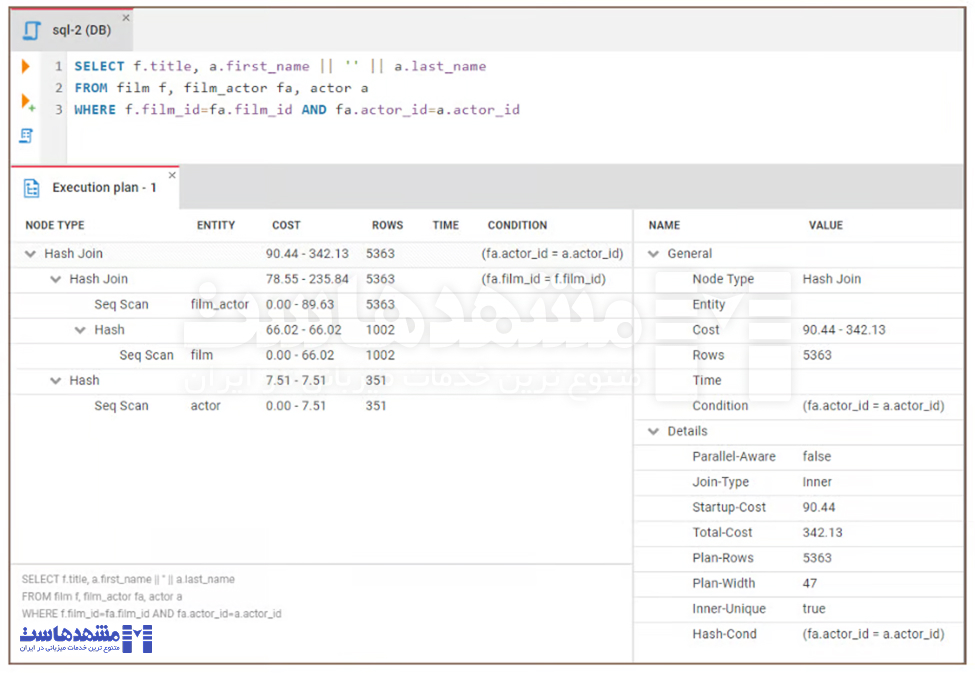
راهنمای کلی برای تفسیر نتایج:
- Full Table Scan: اگر پلن یک اسکن کامل جدول را نشان دهد، دیتابیس هر ردیف جدول را اسکن میکند که میتواند بسیار کند باشد. این اغلب نشاندهنده فقدان ایندکس یا شرط WHERE ناکارآمد است.
- استراتژیهای Join ناکارآمد: پلن میتواند نشان دهد که آیا دیتابیس از الگوریتم Join کمتر بهینه استفاده میکند.
- سایر مشکلات احتمالی: پلنهای EXPLAIN میتوانند مشکلات دیگری مانند هزینههای بالای مرتبسازی یا استفاده بیش از حد از جدولهای موقت را نشان دهند.
6. بهینهسازی شرطهای WHERE برای کاهش حجم دادههای پردازششده
شرط WHERE در کوئریهای SQL ضروری است زیرا به ما امکان میدهد دادهها را بر اساس شرایط خاص فیلتر کنیم و فقط رکوردهای مرتبط را بازگردانیم. این کار با کاهش حجم دادههای پردازششده، کارایی کوئری را بهبود میبخشد، که برای کار با مجموعه دادههای بزرگ بسیار مهم است.
استفاده صحیح از WHERE باعث کاهش پردازش دادههای غیرضروری و بهبود عملکرد SQL میشود.
چند روش برای بهرهبرداری از این شرط:
- اعمال شرایط فیلتر اولیه: گاهی داشتن شرط WHERE کافی نیست. باید دقت کنیم که شرط را کجا قرار میدهیم. فیلتر کردن هرچه بیشتر ردیفها در ابتدای شرط WHERE میتواند به بهینهسازی کوئری کمک کند.
- اجتناب از استفاده از توابع در ستونهای WHERE: وقتی تابعی را روی یک ستون اعمال میکنیم، دیتابیس باید آن تابع را به هر ردیف جدول اعمال کند قبل از اینکه بتواند نتایج را فیلتر کند. این کار مانع استفاده مؤثر از ایندکسها میشود.
مثال ناکارآمد:
SELECT *
FROM employees
WHERE YEAR(hire_date) = 2020;مثال کارآمد:
SELECT *
FROM employees
WHERE hire_date >= '2020-01-01' AND hire_date < '2021-01-01';- استفاده از عملگرهای مناسب: باید کارآمدترین عملگرهایی را انتخاب کنیم که نیازهایمان را برآورده میکنند. برای مثال، = معمولاً سریعتر از LIKE است و استفاده از محدودههای تاریخ خاص سریعتر از توابعی مانند MONTH(order_date) است.
مثال ناکارآمد:
SELECT *
FROM orders
WHERE MONTH(order_date) = 12 AND YEAR(order_date) = 2023;مثال کارآمد:
SELECT *
FROM orders
WHERE order_date >= '2023-12-01' AND order_date < '2024-01-01';7. بهینهسازی Subqueryها
در برخی موارد، هنگام نوشتن یک کوئری احساس میکنیم نیاز به فیلتر کردن، تجمیع یا Join دادهها بهصورت پویا داریم. نمیخواهیم چندین کوئری انجام دهیم؛ بلکه میخواهیم همهچیز را در یک کوئری نگه داریم.
برای این موارد میتوانیم از Subqueryها استفاده کنیم. Subqueryها در SQL کوئریهایی هستند که داخل کوئری دیگری، معمولاً در دستورات SELECT، INSERT، UPDATE یا DELETE، قرار میگیرند.
Subqueryها میتوانند قدرتمند باشند، اما استفاده بیش از حد یا نادرست باعث کاهش عملکرد SQL میشوند. بهعنوان یک قاعده، باید استفاده از Subqueryها را به حداقل برسانیم و مجموعهای از بهترین روشها را دنبال کنیم:
- جایگزینی Subqueryها با Joinها در صورت امکان: Joinها معمولاً سریعتر و کارآمدتر از Subqueryها هستند.
- استفاده از CTEها بهجای Subqueryها: CTEها (Common Table Expressionها) کد ما را به چند بخش کوچکتر تقسیم میکنند که خواندن آنها بسیار آسانتر است.
WITH SalesCTE AS (
SELECT salesperson_id, SUM(sales_amount) AS total_sales
FROM sales GROUP BY salesperson_id
)
SELECT salesperson_id, total_sales
FROM SalesCTE WHERE total_sales > 5000;- استفاده از Subqueryهای غیرمرتبط (Uncorrelated): Subqueryهای غیرمرتبط از کوئری خارجی مستقل هستند و تنها یکبار اجرا میشوند، در حالی که Subqueryهای مرتبط برای هر ردیف کوئری خارجی اجرا میشوند.
8. استفاده از EXISTS به جای IN برای افزایش عملکرد کوئری
هنگام کار با Subqueryها، اغلب نیاز داریم بررسی کنیم که آیا یک مقدار در مجموعه نتایج وجود دارد یا خیر. میتوانیم این کار را با IN یا EXISTS انجام دهیم، اما EXISTS معمولاً برای مجموعه دادههای بزرگ کارآمدتر است.
شرط IN کل مجموعه نتایج Subquery را در حافظه میخواند قبل از اینکه مقایسه کند. در مقابل، شرط EXISTS به محض یافتن یک تطابق، پردازش Subquery را متوقف میکند.
مثال استفاده از EXISTS:
SELECT *
FROM orders o
WHERE EXISTS (SELECT 1 FROM customers c WHERE c.customer_id = o.customer_id AND c.country = 'USA');9. محدود کردن استفاده از DISTINCT
تصور کنید در حال کار روی تحلیلی برای ارسال پیشنهاد تبلیغاتی به مشتریان از شهرهای منحصربهفرد هستیم. دیتابیس چندین سفارش از مشتریان یکسان دارد. اولین چیزی که به ذهنمان میرسد استفاده از شرط DISTINCT است.
این تابع برای موارد خاصی مفید است اما میتواند منابع زیادی مصرف کند، بهویژه در مجموعه دادههای بزرگ. چند جایگزین برای DISTINCT:
- حذف دادههای تکراری در فرآیند پاکسازی دادهها: این کار از ورود دادههای تکراری به دیتابیس جلوگیری میکند.
- استفاده از GROUP BY بهجای DISTINCT: وقتی امکانپذیر است، GROUP BY میتواند کارآمدتر باشد، بهویژه وقتی با توابع تجمیعی ترکیب شود.
مثال ناکارآمد:
SELECT DISTINCT city FROM customers;مثال کارآمد:
SELECT city FROM customers GROUP BY city;- استفاده از توابع پنجره (Window Functions): توابعی مانند ROW_NUMBER میتوانند به شناسایی و فیلتر کردن دادههای تکراری بدون استفاده از DISTINCT کمک کنند.
10. بهرهبرداری از ویژگیهای خاص دیتابیس
هنگام کار با دادهها، از طریق SQL با یک سیستم مدیریت دیتابیس (DBMS) تعامل میکنیم. DBMS دستورات SQL را پردازش میکند، دیتابیس را مدیریت میکند و یکپارچگی و امنیت دادهها را تضمین میکند. DBMSهای مختلف امکاناتی مثل Database Hint، پارتیشنبندی و Sharding دارند که میتوانند به بهینهسازی کوئری SQL کمک کنند.
Database Hintها: دستورات خاصی هستند که میتوانیم به کوئریهای خود اضافه کنیم تا اجرای کوئری کارآمدتر شود. این ابزار مفید است اما باید با احتیاط استفاده شود.
مثال در MySQL:
SELECT * FROM employees USE INDEX (idx_salary) WHERE salary > 50000;مثال در SQL Server:
SELECT *
FROM orders
INNER JOIN customers ON orders.customer_id = customers.id OPTION (LOOP JOIN);این hintها بهینهسازی پیشفرض کوئری را نادیده میگیرند و در سناریوهای خاص عملکرد را بهبود میدهند.
پارتیشنبندی و Sharding:
- پارتیشنبندی: یک جدول بزرگ را به چندین جدول کوچکتر تقسیم میکند، هر کدام با کلید پارتیشن خود. کلیدهای پارتیشن معمولاً بر اساس زمان ایجاد ردیفها یا مقادیر عددی آنها هستند. هنگام اجرای کوئری روی این جدول، سرور بهطور خودکار ما را به جدول پارتیشنشده مناسب هدایت میکند.
- Sharding: مشابه است، اما به جای تقسیم یک جدول بزرگ به جدولهای کوچکتر، یک دیتابیس بزرگ را به دیتابیسهای کوچکتر تقسیم میکند که هر کدام روی سرور جداگانهای هستند. کلید Sharding کوئریها را به دیتابیس مناسب هدایت میکند. Sharding سرعت پردازش را افزایش میدهد زیرا بار روی سرورهای مختلف تقسیم میشود.
11. نظارت و بهروزرسانی آمار دیتابیس برای بهینهسازی کوئری SQL
بهروز نگه داشتن آمار دیتابیس برای اطمینان از اینکه query optimizer میتواند تصمیمات آگاهانه و دقیقی در مورد کارآمدترین روش اجرای کوئریها بگیرد، مهم است.
آمار توزیع دادهها در یک جدول (مانند تعداد ردیفها، فراوانی مقادیر و پراکندگی مقادیر در ستونها) را توصیف میکنند و optimizer به این اطلاعات برای تخمین هزینههای اجرای کوئری وابسته است. اگر آمار قدیمی باشند، optimizer ممکن است execution planهای ناکارآمدی انتخاب کند، مانند استفاده از ایندکسهای اشتباه یا انتخاب اسکن کامل جدول به جای اسکن ایندکس کارآمدتر، که منجر به عملکرد ضعیف کوئری میشود.
با این حال، میتوانیم در مواردی که بهروزرسانیهای خودکار کافی نیستند یا نیاز به دخالت دستی است، آمار را بهصورت دستی بهروزرسانی کنیم. در SQL Server، میتوان از دستور UPDATE STATISTICS برای بهروزرسانی آمار یک جدول یا ایندکس خاص استفاده کرد، در حالی که در PostgreSQL، دستور ANALYZE میتواند برای بهروزرسانی آمار یک یا چند جدول اجرا شود.
— بهروزرسانی آمار برای تمام جدولها در دیتابیس فعلی
ANALYZE;— بهروزرسانی آمار برای یک جدول خاص
ANALYZE my_table;12. استفاده از Stored Procedureها
Stored Procedure مجموعهای از دستورات SQL است که در دیتابیس ذخیره میکنیم تا نیازی به نوشتن مکرر همان SQL نداشته باشیم. میتوان آن را بهعنوان یک اسکریپت قابل استفاده مجدد در نظر گرفت.
وقتی نیاز به انجام یک وظیفه خاص، مانند بهروزرسانی رکوردها یا محاسبه مقادیر داریم، کافی است Stored Procedure را فراخوانی کنیم. این میتواند ورودی دریافت کند، عملیاتی مانند کوئری یا تغییر دادهها انجام دهد و حتی نتیجهای بازگرداند. Stored Procedureها سرعت را افزایش میدهند زیرا SQL از قبل کامپایل شده است و کد را تمیزتر و مدیریت آن را آسانتر میکند.
مثال ایجاد Stored Procedure در PostgreSQL:
CREATE OR REPLACE PROCEDURE insert_employee(
emp_id INT, emp_first_name VARCHAR, emp_last_name VARCHAR)
LANGUAGE plpgsql
AS $
BEGIN
-- درج یک کارمند جدید در جدول employees
INSERT INTO employees (employee_id, first_name, last_name)
VALUES (emp_id, emp_first_name, emp_last_name);
END;
$;
-- فراخوانی پروسیجر
CALL insert_employee(101, 'John', 'Doe');13. اجتناب از مرتبسازی و گروهبندی غیرضروری
ما بهعنوان متخصصان داده دوست داریم دادههایمان مرتب و گروهبندیشده باشند تا بهراحتی بتوانیم بینش کسب کنیم. معمولاً از ORDER BY و GROUP BY در کوئریهای SQL خود استفاده میکنیم.
با این حال، هر دو شرط میتوانند از نظر محاسباتی پرهزینه باشند، بهویژه هنگام کار با مجموعه دادههای بزرگ. هنگام مرتبسازی یا تجمیع دادهها، موتور دیتابیس اغلب باید اسکن کامل دادهها را انجام دهد و سپس آنها را سازماندهی کند، گروهها را شناسایی کرده و/یا توابع تجمیعی را اعمال کند که معمولاً از الگوریتمهای منابعبر استفاده میکنند.
برای بهینهسازی کوئریها، میتوانیم از این نکات پیروی کنیم:
- کاهش مرتبسازی: فقط زمانی از ORDER BY استفاده کنیم که ضروری باشد. اگر مرتبسازی ضروری نیست، حذف این شرط میتواند زمان پردازش را بهطور چشمگیری کاهش دهد.
- استفاده از ایندکسها: وقتی ممکن است، اطمینان حاصل کنیم که ستونهای درگیر در ORDER BY و GROUP BY ایندکسگذاری شدهاند.
- انتقال مرتبسازی به لایه برنامه: در صورت امکان، عملیات مرتبسازی را به لایه برنامه منتقل کنیم تا به دیتابیس فشار وارد نشود.
- تجمیع اولیه دادهها: برای کوئریهای پیچیده شامل GROUP BY، میتوانیم دادهها را در مرحلهای زودتر یا در یک Materialized View تجمیع کنیم تا دیتابیس نیازی به محاسبه مکرر همان تجمیعها نداشته باشد.
14. استفاده از UNION ALL بهجای UNION
وقتی میخواهیم نتایج چندین کوئری را در یک لیست ترکیب کنیم، میتوانیم از شرطهای UNION و UNION ALL استفاده کنیم. هر دو نتایج دو یا چند دستور SELECT را که نام ستونهای یکسانی دارند ترکیب میکنند.
شرط UNION ردیفهای تکراری را حذف میکند که به زمان پردازش بیشتری نیاز دارد.
در مقابل، UNION ALL نتایج را ترکیب میکند اما تمام ردیفها، از جمله تکراریها، را نگه میدارد. بنابراین، اگر نیازی به حذف تکراریها نداریم، باید از UNION ALL برای عملکرد بهتر استفاده کنیم.
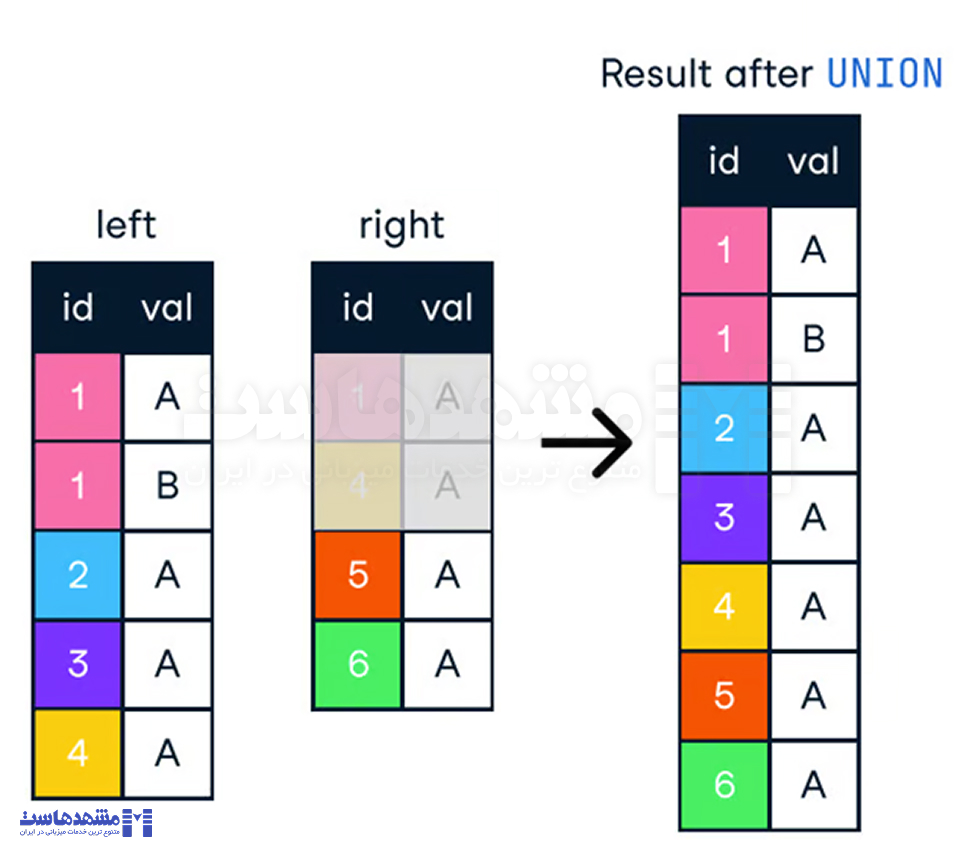
مثال ناکارآمد:
SELECT product_id FROM products WHERE category = 'Electronics'
UNION
SELECT product_id FROM products WHERE category = 'Books';
مثال کارآمد:SELECT product_id FROM products WHERE category = 'Electronics'
UNION ALL
SELECT product_id FROM products WHERE category = 'Books';15. تجزیه کوئریهای پیچیده
کار با مجموعه دادههای بزرگ به این معناست که اغلب با کوئریهای پیچیدهای مواجه میشویم که درک و بهینهسازی آنها دشوار است. میتوانیم با تجزیه آنها به کوئریهای کوچکتر و سادهتر این موارد را مدیریت کنیم. به این ترتیب، شناسایی گلوگاههای عملکرد و اعمال تکنیکهای بهینهسازی آسانتر میشود.یکی از استراتژیهای رایج برای تجزیه کوئریها، استفاده از Materialized Viewها است.
مثال ایجاد و کوئری Materialized View:
-- ایجاد یک Materialized View
CREATE MATERIALIZED VIEW daily_sales AS
SELECT product_id, SUM(quantity) AS total_quantity
FROM order_items
GROUP BY product_id;
-- کوئری Materialized View
SELECT * FROM daily_sales;16. استفاده از INNER JOIN بهجای WHERE برای Joinها
اتصال جدولها با استفاده از شرط WHERE میتواند به ناکارآمدی و محاسبات غیرضروری منجر شود. استفاده از INNER JOIN یا LEFT JOIN برای اتصال جدولها کارآمدتر است.
ناکارآمد:
SELECT GFG1.CustomerID, GFG1.Name, GFG1.LastSaleDate
FROM GFG1, GFG2
WHERE GFG1.CustomerID = GFG2.CustomerIDکارآمد:
SELECT GFG1.CustomerID, GFG1.Name, GFG1.LastSaleDate
FROM GFG1
INNER JOIN GFG2
ON GFG1.CustomerID = GFG2.CustomerID17. محدود کردن Wildcardها به انتهای عبارت جستجو
Wildcardها هنگام جستجوی دادههای رمزنگارینشده، مانند نامها یا شهرها، گستردهترین جستجو را فراهم میکنند. اما گستردهترین جستجو کمکارآمدترین است. استفاده از wildcardهایی مانند % در ابتدای رشته، استفاده مؤثر از ایندکسها را برای SQL دشوار میکند. بهتر است wildcardها را در انتهای عبارت جستجو قرار دهید.
ناکارآمد:
SELECT City FROM GeekTable WHERE City LIKE '%No%'کارآمد:
SELECT City FROM GeekTable WHERE City LIKE 'No%'18. اجرای کوئریها در ساعات کمترافیک
اجرای کوئریهای سنگین در ساعات کمترافیک، بار روی دیتابیس را کاهش داده و تأثیر آن بر سایر کاربران را به حداقل میرساند. بهتر است کوئریها را زمانی اجرا کنید که تعداد کاربران همزمان در کمترین میزان باشد، معمولاً در ساعات شب.
نتیجه گیری:
در این مقاله، استراتژیها و بهترین روشهای بهینهسازی کوئری SQL از ایندکسگذاری و Joinها تا Subqueryها و ویژگیهای خاص دیتابیس بررسی شد. با اعمال این تکنیکها، میتوانید عملکرد کوئریها را بهبود داده، بهینهسازی دیتابیس را تضمین کرده و زمان پاسخگویی کوئریها را کاهش دهید.
بهینهسازی کوئری SQL یک فرآیند مستمر است؛ با رشد دادهها و تکامل برنامهها، باید کوئریها را بهطور مداوم نظارت و بهبود دهید.
منبع: [datacamp.com,geeksforgeeks.org]
